Wikidata is a Giant Crosswalk File

Building a Map Platform Join Table with DuckDB and Some Ruby
Wikidata is Wikipedia’s structuralist younger brother. It’s contents are seemingly exhaustive, but rather than readable articles, Wikidata expresses itself with structured data. Pick a subject and check out it’s page; it’s like reading the back of a baseball card for, well, anything.
And burried in those stats and metadata are external IDs: identifiers from other sites and systems, which we can use to grab more data and develop cross-platform applications. Wikidata has thousands of ‘em.
Today we’re going to build a cross-walk table for places (a topic near and dear to my heart) that you can do with just DuckDB, a short Ruby script, and one hard-earned bash line.
If you want to follow along, grab a recent JSON extract of the Wikidata corpus. But be aware: it’s just shy of 140 GB.
Wrangling the Download
Please do not extact the file you just downloaded. It’s big enough to potentially cause problems on your machine and will definately be unweildy. We need to break it down into chunks, so we can concurrently process it later.
Now Wikidata very helpfully produces this file so each item is on it’s own line.
However, for reasons unknown to me, they wrap these neatly separated rows with brackets ([ and ]) and add a comma to each line so it’s a valid, JSON array containing 100+ million items. So close, Wikidata. Please check out JSON Lines…
We are not going to attempt to load a this massive array. Instead, we’re running this command:
zcat ../latest-all.json.gz | sed 's/,$//' | split -l 100000 - wd_items_cw --filter='gzip > $FILE.gz'
This hard-won line streams the uncompressed content into sed, which removes the trailing commas, then chunks the output into batches of 100,000 records which are finally gzipped into files.
Now we can use DuckDB!
SELECT count(*) FROM 'wd_items_*.jsonl.gz';
It takes a bit, but returns a count of ~107 million entities.
Exploring the Wikidata Schema
Let’s look at a record to see what we’re dealing with:
COPY (select * from 'wd_items_*.jsonl.gz' limit 1) to 'sample_record.json';
This is the record for Belgium and it’s a big one: 48,252 lines of formatted JSON. Let’s take a high-level tour of the entity structure:
- There’s the basic, top-level values like
type,id, and a timestamp noting when it was last modified. - The
labelsdictionary contains localized strings of the item’s name in many languages (Belgium has 323 labels). This dictionary uses a language code as a key (“en” for English, for example), which maps to a dictionary containing the localized value and a seemingly redundant langauge code. (I can’t figure out why the language code’s there twice! Let me know below, if you do.) - The
descriptionandaliasesdictionary are similar in form to thelabelsdictionary, just with localized descriptions and aliases, respectively. - The
sitelinksdictionary contains links to associated pages on other WikiMedia platforms. For example, the English-langauge Wikiquote page for Belgium. - But what we care about today is the
claimsdictionary…
Wikidata claims are a key-value system similar in nature to OpenStreetMaps’ tag system, and likley adopted for similar reasons. It’s a flexible, folksonomic system that facillitates broad collaboration and diverse data elements. Wikidata claims can also join one element to another, and describe the relationship. For example, Belgium is part of the European Union. There can also be more than one claim of the same type: Belgiun is also part of the Allies of the First World War, Europe, and the Low Countries
The claims we’re after today are those describing an external IDs. Thankfully, they’re labeled clearly for us:
{
"mainsnak": {
"snaktype": "value",
"property": "P7127",
"datavalue": {
"value": "belgium",
"type": "string"
},
"datatype": "external-id"
},
"type": "statement",
"qualifiers": null,
"qualifiers-order": null,
"id": "Q31$be99eedf-4d68-b90b-e95b-21438633aa8d",
"rank": "normal",
"references": null
}
This claim describes the AllTrails ID for Belgium. The value under mainsnak and datavalue is the AllTrails ID itself. The property under mainsnak is the claim identifier for AllTrails IDs. (And no, I don’t know why they’re named snaks)
There are 214 external ID claims for Belgium!
Want the Library of Congress number?
Or how about the ID for the libraries of Ireland, Iceland, or Greece?
You can find stories about Belgium on the BBC, The Guardian, or C-SPAN.
Find all the videogames Belgium appears in on Giant Bomb or find code tagged with belgium on Github.
Most interesting to me: geo identifiers like OpenStreetMap, Google Maps, and Who’s On First all have claims. And for many records, Apple Maps IDs are there too.
Today we’re going to build a giant crosswalk file for all the geographic entities on Wikidata.
Preparing the Entities
Our folder full of gzipped JSONL files is good, but there’s a ton of metadata in there we don’t need and is in a more difficult format than necessary. We’ll use a small Ruby script to prep the data:
Our process_file function walks through each gzipped file, line by line, skipping items if they don’t have English-language labels or descriptions. We assemble a subset of claims with confident rankings and data values, then save the item as a JSON line in our filtered JSONL file. Gone are all the localizations and the complexity of the claims, since we’re only taking one claim per claim type (so just dictionaries, no arrays). That’s a good trade off for our use case today.
Processing 535 chunked files is a great use case for Ruby Ractors, which let us run our processing code concurrently across multiple cores. It takes awhile to run, but this script turns our ~135 GBs of gzipped files into ~45 GBs of uncompressed JSONL.
Building the Crosswalk
With the claims normalized into a dictionary linking only to objects of the same type (no arrays), it is treated as a map, not a struct by DuckDB. Which will let us build our crosswalk just using DuckDB.
We’re going to use the UNNEST function which lets us turn an array into rows for each item. UNNEST is a SQL feature in many databases which allow arrays, but it’s both a function and a pun in DuckDB.
SELECT COUNT(unnest(map_values(claims))) FROM 'filter/*.jsonl';
Which returns 66,429,868 claims across 3,634,596 different entities.
Let’s whittle that down to only the claims describing external IDs:
SELECT name, claim[1].mainsnak
FROM (
SELECT name, UNNEST(map_values(claims)) as claim
FROM 'filter/*.jsonl'
)
WHERE claim[1].mainsnak.datatype = 'external-id';
23,689,931 claims, or ~35% of all claims. Let’s parse that mainsnak a bit to produce our first, proper crosswalk:
SELECT
name as wikidata_id,
claim[1].mainsnak.property as property,
CAST(claim[1].mainsnak.datavalue.value AS VARCHAR) as external_id
FROM (
SELECT name, UNNEST(map_values(claims)) as claim
FROM 'filter/*.jsonl'
)
WHERE claim[1].mainsnak.datatype = 'external-id';
The datavalue is being returned as a JSON for some reason, so we’re casting it as VARCHAR. I’m sure there’s a more elegant way, but still: this builds us a crosswalk table with 23,689,931 ID pairs, in about 45 seconds on my Mac Studio.
But we can do better. Boot up DuckDB targeting a database file with: duckdb geo_cross.db
Load our previous query as a table:
CREATE TABLE wikidata_external_join AS
SELECT
name as wikidata_id,
claim[1].mainsnak.property as property,
CAST(claim[1].mainsnak.datavalue.value AS VARCHAR) as external_id
FROM (
SELECT name, UNNEST(map_values(claims)) as claim
FROM 'filter/*.jsonl'
)
WHERE claim[1].mainsnak.datatype = 'external-id';
And create a table with the names and descriptions for each item:
CREATE TABLE wikidata_entities AS SELECT name as id, label as name, description FROM 'filter/*.jsonl';
And just for fun, let’s grab one non-external-id claim: P625.
CREATE TABLE coordinates AS
SELECT
name as wikidata_id,
claim[1].mainsnak.datavalue.value.latitude as latitude,
claim[1].mainsnak.datavalue.value.longitude as longitude
FROM (
SELECT name, UNNEST(map_values(claims)) as claim
FROM 'filter/*.jsonl'
)
WHERE claim[1].mainsnak.property = 'P625';
Property P625 is coordinate location, which handily contains a JSON dictionary with latitude and longitude values. There are 1,453,456 items with coordinates!
Let’s plot them out:
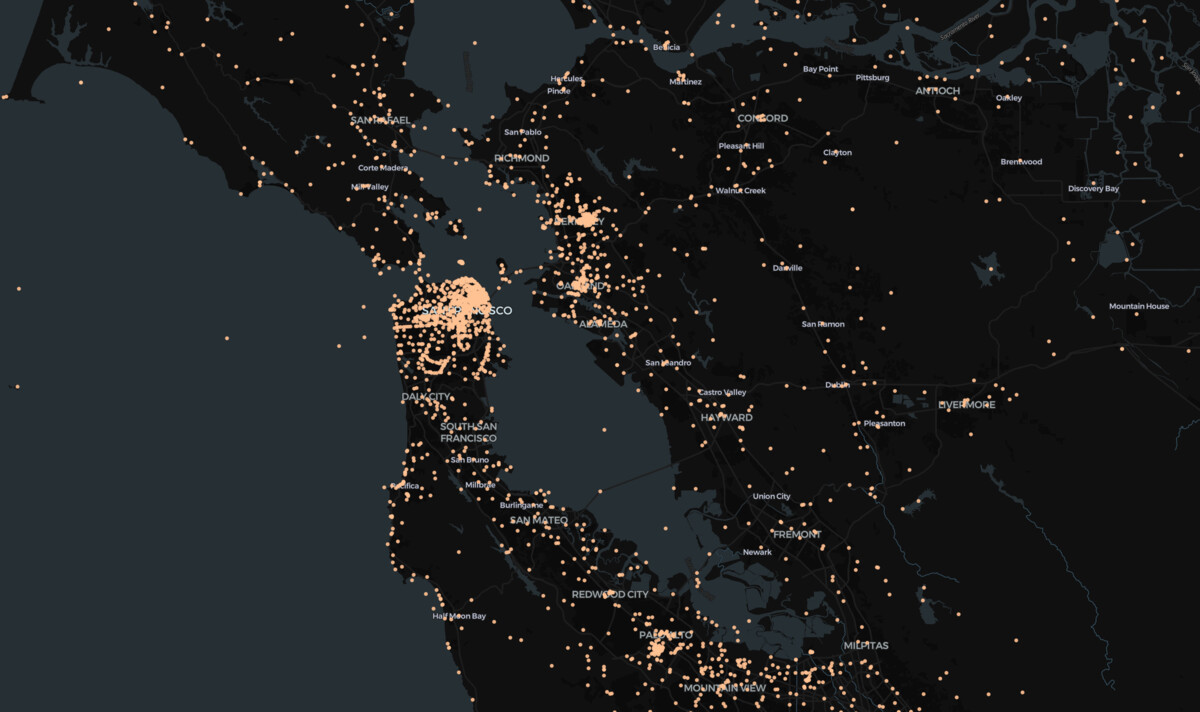
Pretty good! Our loaded geo_cross.db is only ~500 MBs. The only bit missing is a table of labels for the ids in the property column of the join table. That’s out of scope for this article, but I will leave you with this CSV listing seven different external map identifiers:
With this you can run:
CREATE TABLE properties AS SELECT * FROM 'geo_id_properties.csv';
Then with a hacked-together SQL pivot, voila: a 371,937 record matchfile, with coordinate pairs.
And you could take this much further. Wikidata has claims for parent/child relationships among adminstrative areas. And claims specifying something is part of another entity…
Wikidata is a sleeper of a crosswalk file. It tracks over 7,669 different external IDs. Sure, there’s noise in there,but there’s so much potential.