On Test-Time Compute: The New Game in Town
What can we learn from December’s LLM blitz and o3’s arrival?
December was such a big month for LLMs, looking at the previous 11 months in the rear-view it feels like everything was a quiet build up to this moment. Both Ethan Mollick and Simon Willison posted nice wrap-ups, check those out if you want all the details.
Let’s quickly run down the hits:
- Meta shipped Llama 3.3 instruct, a high-quality and efficient open model capable of fitting GPT-4 performance on higher-end consumer laptops, as well as efficiently running on the usual endpoints.
- Microsoft released Phi-4, a lightweight model that excels at STEM tasks. The Phi team continues to push the boundary on effectively using synthetic data to train lightweight yet capable models.
- Google pushed out Gemini 2.0 Flash two weeks ago, an excellent LLM capable of streaming voice, text, and video conversations. They then fast-followed with Flash Thinking Mode – a reasoning model on par with o1-pro.
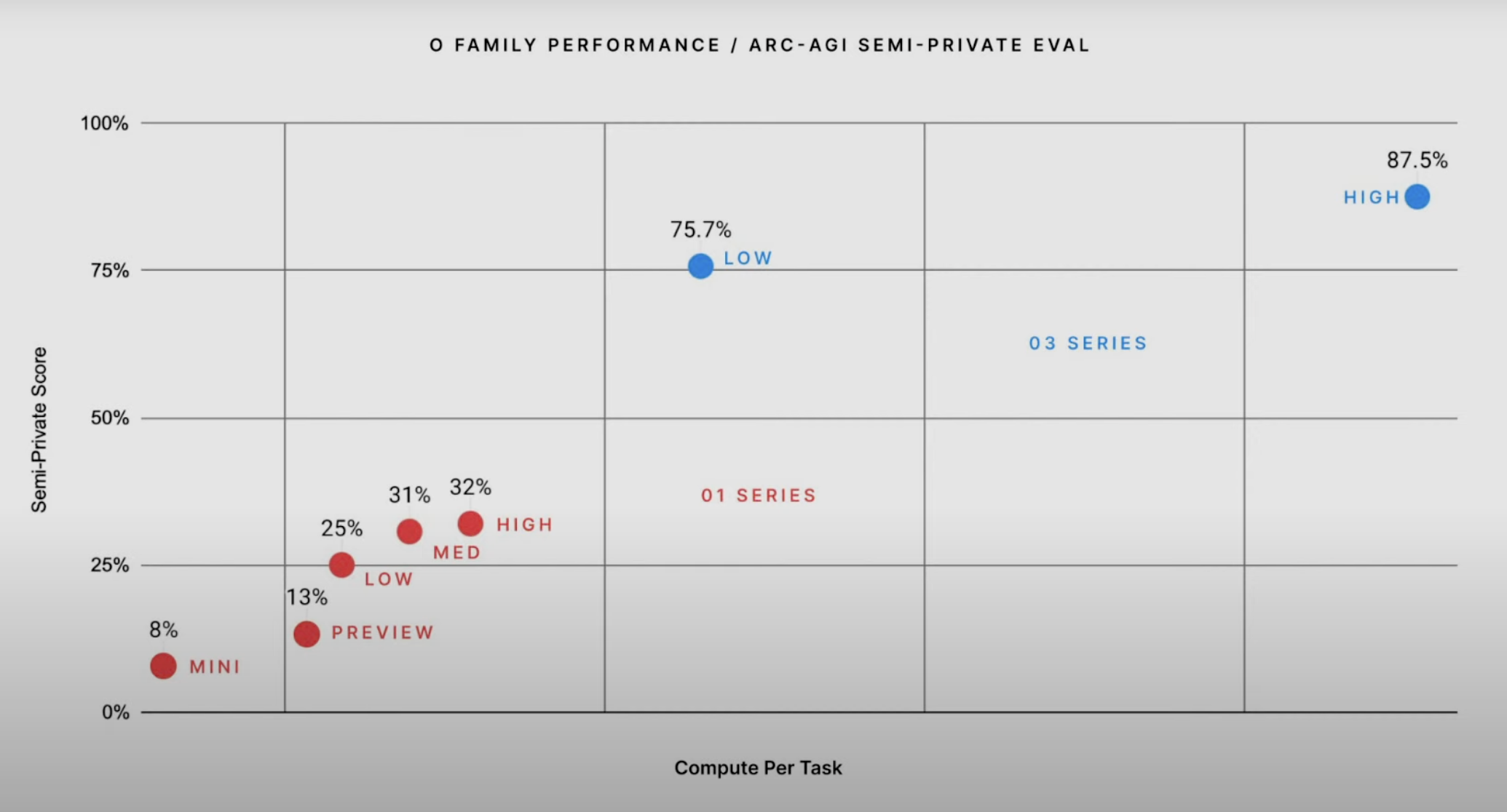
- And then there’s OpenAI’s o3, a new reasoning model that delivered step-change performance on the most respected reasoning benchmark, ARC-AGI-1. This test is hard: GPT-3 scored 0% and 4 years later GPT-4o scored 5%. The o3 model scores 75%. This score is dramatic enough that it solidifies the o-series’ tactics – leveraging chain-of-thought training, searching for several approaches to a problem, then applying and backtracking if necessary these approaches to a task – as the new scaling law. Work on these will be the focus for 2025.
There will be much written about o3, but François Chollet’s piece on it is excellent. Go read it.
This blitz of new models shows the pace of innovation isn’t slowing down, despite the demise of LLM’s foundation scaling law. Looking at this all, there’s a few immediate take-aways:
-
The best models will think longer: “Test-time compute” (aka, spending more time printing tokens to reason about a problem) is now fully established as a new scaling law. The o-series’ record on ARC-AGI underscores this (see the image above): spending 175 times more compute per task moved o3’s ARC-AGI score from 7% to 87%.
-
We’re gonna need more chain-of-thought training data: To enable effective longer “reasoning” we need chain-of-thought data where arguments and presentations are spelled out linearly. These datasets are either hand-created (hiring a bunch of math undergrads was OpenAI’s first approach) or synthesized (the Phi team at Microsoft use larger models to extract reasoning from high quality content). We need this data to teach LLMs to “think” longer. There will be continued investment in creating this more complex training data.
-
There will be an increased focus on inference: We’re going to spend a lot more on inference this year – (1) to generate the synthetic reasoning data we need to train new models, (2) to generate longer answers from chain-of-thought models, and (3) to bring these tiny GPT-4 class models to life at the edge. I think this is going to get interesting. There’s potential for gains from optimized NPU software and alternatives to NVIDIA are more relevant for inference use cases, especially when you don’t need a large mult-node cluster.
-
Builders need to stay flexible: If you’re building apps or pipelines powered by LLMs, this month has underscored the need to remain flexible. No matter your task, a better and cheaper model is right around the corner. Invest in testing infrastructure specific to your use cases so you can repeatedly trial new models and move on.