Your Eval is More Important Than the Model
Before You Pick a Model or Write a Prompt: Build an Eval
In this Cambrian era of LLMs – where new models drop every week – choosing a model for a product, pipeline, or project can be daunting. It’s tempting to throw your hands up and default to whatever OpenAI or Anthropic is offering this week. But if you’re building with AI, I strongly recommend against this “default.” Instead, take a step back and build your eval.
This might seem counterintuitive and/or a bit discouraging. It’s more fun to play with models, try out prompts, and push forward. Building a dataset is slow, tedious, and, well…not exactly exciting.
But evals are essential.
Last year, Hamel Husain wrote an amazing piece on evals, arguing, “If you streamline your evaluation process, all other activities become easy.” I’ll go a step further: your eval is the most valuable AI asset you own, not your model or your prompts.
A well-built custom eval lets you quickly test the newest models, iterate faster when developing prompts and pipelines, and ensure you’re always moving forward against your product’s specific goal. And perhaps the most important takeaway from last month’s deluge of new models is that builders must be flexible. A better, cheaper model will arrive tomorrow. Armed with a tailored eval, you can evaluate it in an afternoon.
As OpenAI’s Greg Brockman said, “Evals are surprisingly often all you need.”
In this post, we’ll build our own eval and show how quickly it can inform decisions and facilitate development.
Sections
- Assembling the Dataset
- Generating Responses
- Evaluating Responses
- Our Results (click here to skip all the code!)
- Iterating Faster With Our Eval
- Building Your Own Eval is Essential

A Knowledge Bank Test: The J1k Eval
For the purposes of this post, let’s assume we’re building a Jeopardy-style iOS trivia app. The trivia questions are frequently updated and people can play against their friends or a computer. The “computer” in this case will be an LLM, preferably one small enough to run on the phone. We’d like to run the LLM at the edge to cut down on costs and to enable offline play.
We want to find the small model that can best answer trivia questions while running locally on a phone. To do this, we need to assemble a dataset, generate responses, and evaluate responses.
Assembling the Dataset
Given our product, we’re going to build a dataset from Jeopardy questions. We obtained a dataset of Jeopardy clues and their categories, answers, and dollar values. These dollar values – ranging from $100 to $1000 – are a good proxy for question difficulty. Assembling our initial eval dataset, we select 1,000 questions, each from a different category and evenly distributed among the dollar values. These records are output to a single JSONL file we call test_questions.jsonl.
Here’s an example record:
{
"value": 500,
"category": "FLAGS",
"clue": "Term for a national flag displayed on a ship, it's also the lowest commissioned rank in U.S. Navy",
"answer": "ensign"
}
This is our eval dataset, which we call J1k1.
Generating Responses
Armed with this data, we need to generate responses from a variety of models, tracking their output and speed. A simple Python script will do:
import json
import time
import dspy
# Load the test questions
def load_test_questions(file_path, num_questions=1000):
with open(file_path, 'r') as file:
questions = [json.loads(line) for line in file]
questions = questions[:num_questions]
return questions
test_questions = load_test_questions('test_questions.jsonl')
# Specify the models we wish to test
models = [
'llama3.2:1b',
'llama3.2:latest',
'llama3.3:latest',
'llama3.1:latest'
]
# Define our DSPy Signature
class BuzzIn(dspy.Signature):
"""Answer a trivia question with the correct answer."""
clue: str = dspy.InputField()
answer: str = dspy.OutputField()
buzz_in = dspy.Predict(BuzzIn)
# Generate answers for each model and log the time taken
with open('time_to_compute.txt', 'w') as time_log:
for model in models:
start_time = time.time()
with open(f'answers/answers_{model}.jsonl', 'w') as f:
for question in test_questions:
with dspy.context(lm=dspy.LM(f"openai/{model}", api_base='http://localhost:11434/v1', api_key='ollama')):
answer = buzz_in(clue=question['clue'])
f.write(json.dumps({
"clue_id": question['id'],
"model": model,
"clue": question['clue'],
"answer": answer.answer,
"correct_answer": question['answer']
}) + '\n')
# Log the test time
end_time = time.time()
elapsed_time = end_time - start_time
time_log.write(f"{model}: {elapsed_time:.2f} seconds\n")
# Print the status
print(f"Model {model} took {elapsed_time:.2f} seconds")
print(f"Answers for model {model} written to answers_{model}.jsonl")
This is ~50 lines of code which can generate answers from any model we wish. We’re using the DSPy framework again, as it helps us quickly stand up our prompt, parse the output, and easily cycle through different models.
But how you generate responses doesn’t need to be complex. What matters most when getting started is the ability to easily change the model(s) you’re using.
Evaluating the Responses
To evaluate our responses, we’ll be using an LLM as a judge2 to determine if the generated answers are correct. But before we write our evaluator, we need to scan our responses and understand how the models fail.
Here’s an example of a clearly wrong answer:
Clue: "Member of the lute family mentioned in the lyrics of 'Oh Susanna'"
Answer: "banjo"
LLM Response: "Bass"
Model: llama3.2:1b
If all the wrong answers were this straightforward, we wouldn’t need to use an LLM judge. But unfortunately, there are plenty of correct answers that would fail simple comparison tests.
Here’s one
Clue: "This Connecticut Yankee invented the revolver in 1836, not '.45'"
Answer: "(Samuel) Colt"
LLM Response: "The correct answer is Samuel Colt."
Model: llama3.2:1b
The model got it right, but the correct answer has parentheses (indicating the first name is optional on Jeopardy) and the response is a complete sentence.
Scanning over the responses, we make a list of common discrepancies:
- Varying punctuation (“ten gallon hat” vs “ten-gallon hat”)
- Optional articles (“Danube” vs “the Danube”)
- Pluralization (“Cat” vs “Cats”)
- Capitalization (“Bargain” vs “bargain”)
- More or less specificity (“The Biograph” vs. “The Biograph Theater”)
- Spelling numbers (“2” vs “Two”)
These discrepancies are common enough that it’s worth formatting these strings and performing some simple match techniques before throwing the call to our LLM judge:
Here’s our string cleaner:
def prepare_answer_text(answer: str) -> str:
answer = answer.lower()
# Remove punctuation
answer = answer.replace('(', '').replace(')', '')
answer = answer.replace('.', '').replace(',', '').replace('!', '').replace('?', '')
answer = answer.replace('\'', '').replace('\"', '')
# Remove articles
articles = ['a ', 'an ', 'the ']
for article in articles:
if answer.startswith(article):
answer = answer[len(article):]
return answer
And our initial evaluator:
import editdistance
import inflect
p = inflect.engine()
def evaluate_model_answer(given_answer, correct_answer):
correct_answer = prepare_answer_text(answer=str(correct_answer))
given_answer = prepare_answer_text(answer=str(given_answer))
# Check if the distance between the two is less than 2
distance = editdistance.eval(correct_answer, given_answer)
if distance < 2:
return True
# Check if the edit distance is .30 or less of the length of the correct answer
if distance <= len(correct_answer) * .30:
return True
# # Then check if they match if either is pluralized
try:
given_answer_plural = p.plural(given_answer)
if correct_answer in given_answer_plural or given_answer_plural in correct_answer:
return True
except:
return False
# # Check if either is a number and compare numeric spelling
if correct_answer.isdigit():
correct_answer_in_words = p.number_to_words(correct_answer)
if given_answer in correct_answer_in_words:
return True
return False
There are, of course, responses which will frustrate these comparisons. Here’s one:
Clue: "Not the Master of the House, but the Master of the this is responsible for the sovereign's carriages & certain animals"
Answer: "Horse"
LLM Response: "Master of the Horse"
Model: llama3.3:latest
This is why we need to fall back to an LLM judge, which we define like so:
class JudgeResponse(dspy.Signature):
"""Evaluate a model's answer to a Jeopardy clue, compared to the correct answer."""
clue: str = dspy.InputField(desc="the Jeopardy clue")
correct_answer: str = dspy.InputField(desc="the correct answer to the clue")
given_answer: str = dspy.InputField(desc="the answer given by the model")
correct: bool = dspy.OutputField(desc="whether the model's answer is correct or not")
judgeResponse = dspy.Predict(JudgeResponse)
For each response, we then follow this process:
simple_judgement = evaluate_model_answer(given_answer, correct_answer)
if naive_evaluation:
print("Simple Correct")
else:
llm_judgement = judgeResponse(clue=clue, correct_answer=correct_answer, given_answer=given_answer)
if llm_judgement.correct:
print("LLM Correct")
else:
print("Incorrect")
Replace those print statements with logging calls and step through all your responses.
This multistep pipeline – a compound AI system – might seem complex, but it saves us time: for some models, 60% of responses never hit an LLM. Further, you (or, preferably, your domain expert) should be reviewing the responses by hand anyway to understand how failure occurs, so you might as well spot the simple judgments.
The above evaluation pipeline is simple but it’s ready to grow. As you grow your dataset and get more examples of correct and incorrect judgments calls, you can optimize your DSPy judge signature and potentially step it down to a smaller model – speeding up your pipeline further. Remember: one of the big advantages of having an eval is that it speeds up iteration, letting your products advance faster. Improving your eval data and your harness further improves your velocity, yielding cumulative benefits.
Our Results
We threw four llamas and six Qwen 2.5 variants at our eval, yielding these results:
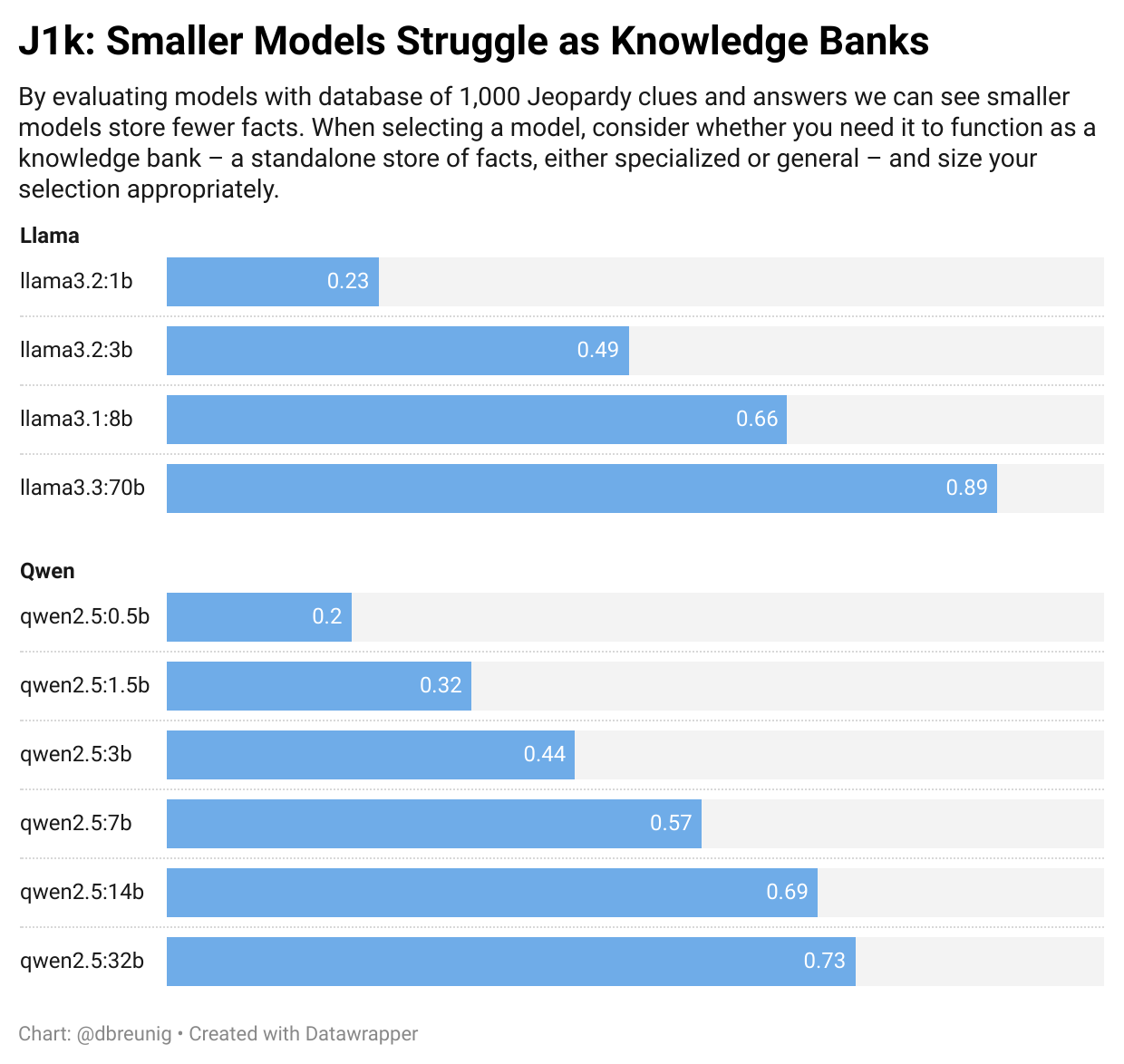
We see a clear correlation between a model’s size and its ability to function as a “knowledge bank.” The Qwen 2.5 section provides the clearest illustration of this, as every step up in size yields an increase in accuracy, though this has diminishing returns. Going from 0.5b parameters to 1.5b triples the size while increasing performance by 65%. But going from 14b to 32b more than doubles our parameters while only yielding a 6% accuracy gain.
Increasing the size of the model also increases our inference time, something that will directly affect a model’s suitability as a trivia opponent:
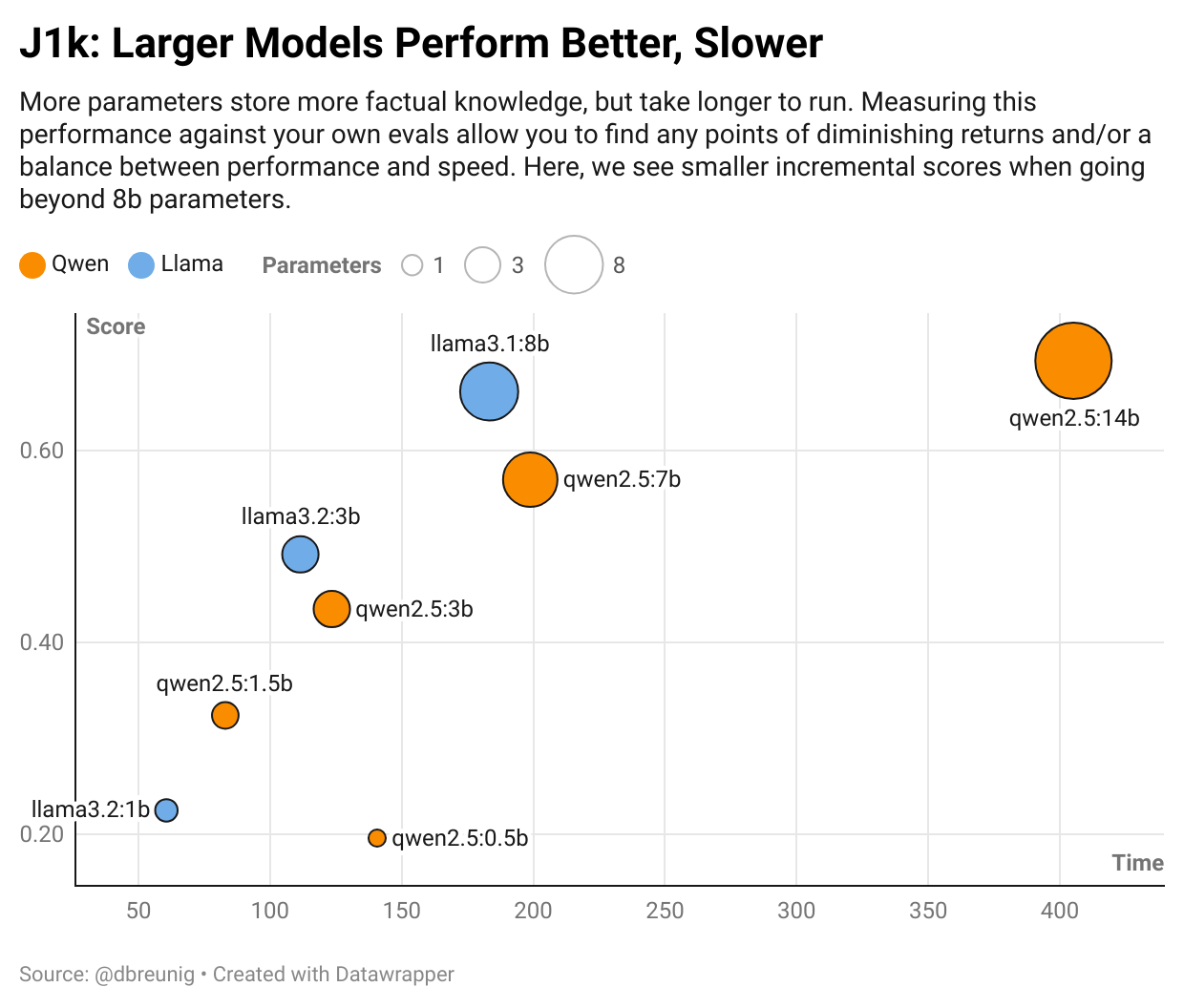
Looking at this view crystalizes our options: increasing our parameters beyond 8b significantly increases our inference time in exchange for a slight improvement in accuracy3. (I left Llama 3.3 70b off this chart: it took ~1,300 seconds.)
Iterating Faster With Our Eval
Having an eval doesn’t just help with model selection – it helps as you try to improve the ability of your model.
For our iOS trivia app, we’ve determined that while an 8b parameter model delivers great results, it takes too long to produce them. We don’t want our players waiting that long, so let’s try improving Llama 3.2 3b.
We have a few options to increase its accuracy:
- Tool Use: Enable the LLM to reference a remote or local dataset to inform its answers4
- Prompt Engineering: Can we write a prompt that’s better suited to answering Jeopardy questions? Should we encourage chain-of-thought or use a multi-shot technique?
- Fine Tuning: Can we fine tune our model on a knowlege base relevant to our trivia questions? This is our last resort as it’s the most effort and will likely increase our model size. Not a great fit for our goals here.
Thanks to DSPy, we can try a new prompting technique with one change:
class BuzzIn(dspy.Signature):
"""Answer a trivia question with the correct answer."""
clue: str = dspy.InputField()
answer: str = dspy.OutputField()
# buzz_in = dspy.Predict(BuzzIn)
buzz_in = dspy.ChainOfThought(BuzzIn)
The ChainOfThought module executes our signature with a prompt that asks the LLM to think step-by-step before committing to an answer.
Does it work?
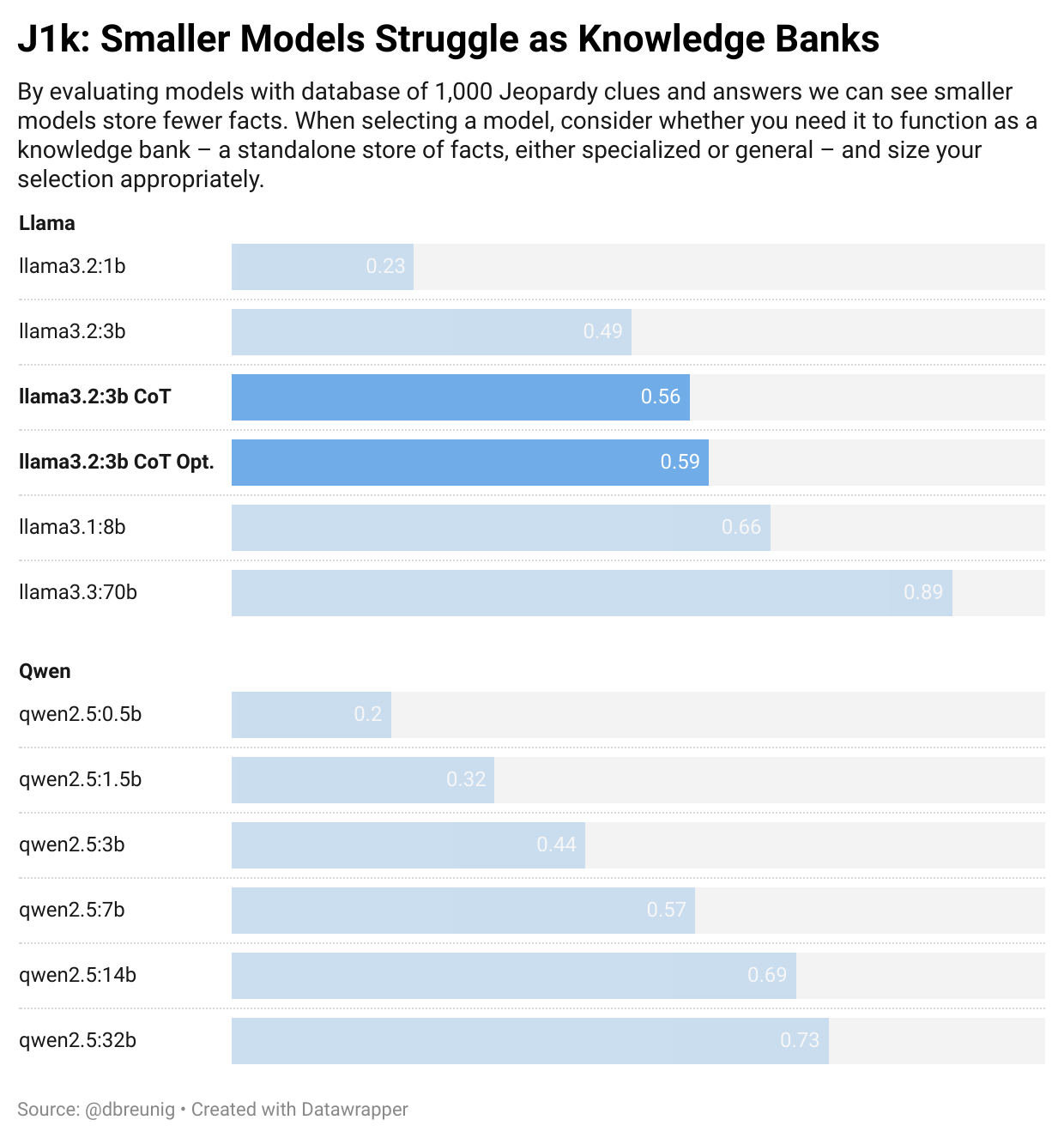
Yes! Chain-of-thought prompting yields a 14% accuracy boost. If we ask DSPy to optimize our signature, using our dataset of Jeopardy clues and answers as a training set, we see a full 20% performance boost.
But our eval indicates there’s a cost: chain-of-thought means more inference which means this accuracy takes more time. This simple test took 10x longer than our initial technique. Too long for general usage, but you can envision some cases where it’s appropriate to give a computer opponent more time to ponder.
Building Your Own Eval is Essential
Every time a new model launches, the same alphabet soup of benchmarks is rolled out. Check out the just-landed Phi-4:
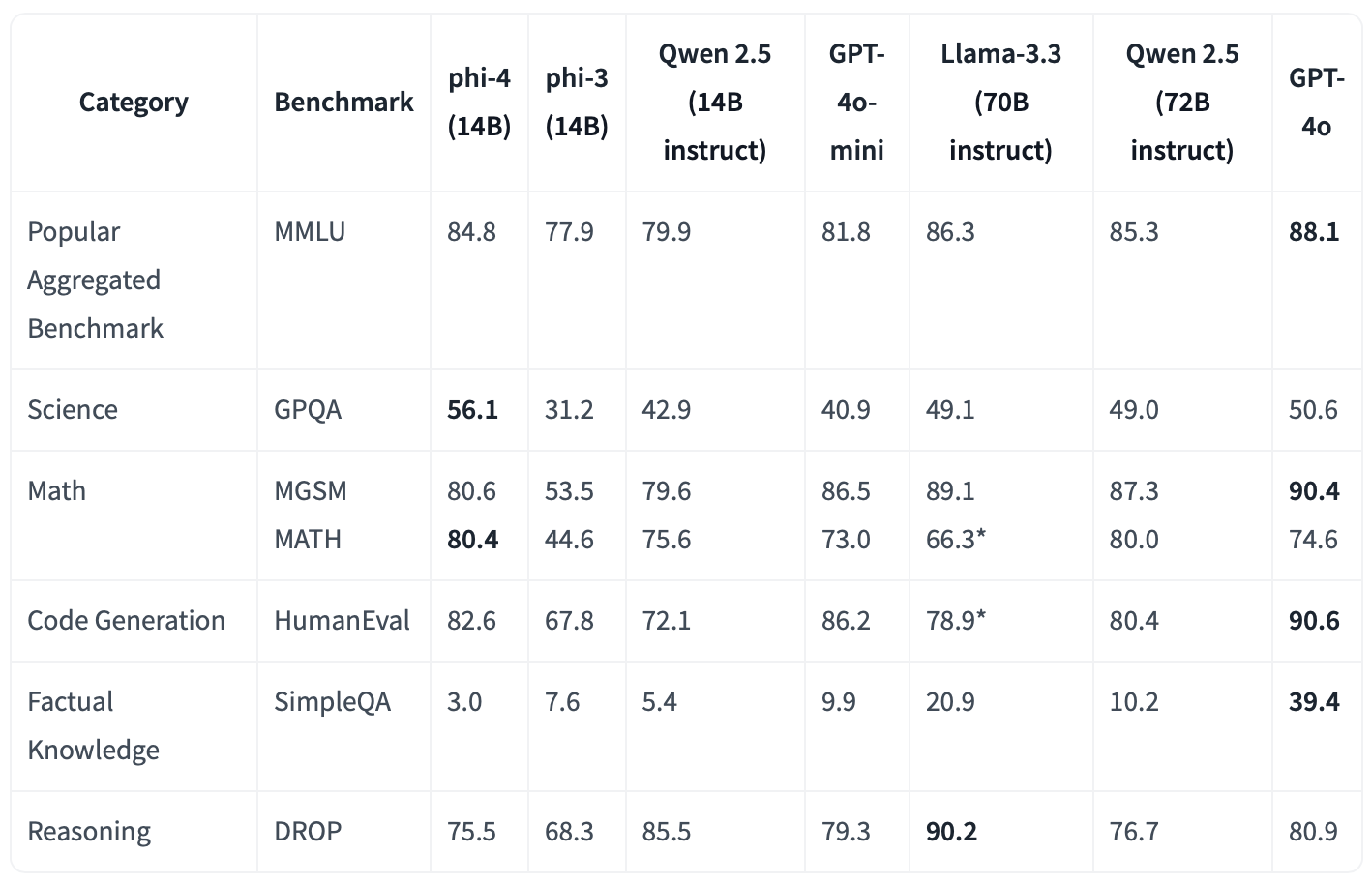
These figures give us a pretty good sense of Phi-4’s capabilities, but the quirks of each model – and how much they matter to you – can only be determined with an eval designed for your use case. None of these evals are built with your app in mind.
The AI landscape moves incredibly fast – last year’s state-of-the-art is today’s baseline. Having an eval gives you a constant north star. Our J1k eval demonstrates how easy it is to get started and how quickly we can realize the benefits: it revealed the tradeoffs between size and performance, helped us select a model suited to our use case, and gave us a framework for rapidly testing improvements and whatever novel model lands tomorrow.
The real power of a custom eval isn’t just in model selection – it’s in the compound benefits it delivers over time. Each new model can be evaluated in hours, not weeks. Each prompt engineering technique can be tested systematically. And perhaps most importantly, your eval grows alongside your understanding of the problem space, becoming an increasingly valuable asset for your AI development.
-
While looking for a page to serve as a backgrounder on the LLM-as-a-judge concept, I learned Hamel Husain has written a deep dive on this technique. It’s pure gold. ↩
-
I have no idea why Qwen 2.5 0.5b is taking as long as it does. I reran this test several times with several different configs and the results were consistent. I’m curious though… If you have an explanation, please, let me know ↩
-
Our example is getting a little contrived now, but work with me here! ↩