What We Mean When We Say “Think”
What exactly are “reasoning” and “thinking” models?

Last September, OpenAI launched its first “reasoning” model, o1. Unlike previous models, o1 “thinks” before delivering a final answer, chewing on a problem with step-by-step notes. OpenAI explained,
Similar to how a human may think for a long time before responding to a difficult question, o1 uses a chain of thought when attempting to solve a problem.
This tactic delivered incredible results, at least for programming and math applications. OpenAI’s o1 model scored 6 times higher than the non-reasoning GPT-4o when answering competitive math questions and 8 times higher when solving coding challenges.
Suddenly, every AI lab was building and releasing reasoning models. Four months later, DeepSeek’s arrival made these models a household name. Today, Claude has “thinking modes” and ChatGPT has a “reason” button.
But how exactly did these models learn to “reason”? What do we mean when we say, “think”? Why do reasoning models excel at coding and math, but struggle to show improvements when venturing beyond these domains?
Today let’s look at how we arrived at reasoning models, review how they’re built, and examine their impact on the ecosystem.
Like everything else in AI, reasoning models aren’t magic. They just haven’t been clearly explained.
ToC / tl;dr
This is a longish piece. If you're familiar with the domain, feel free to skip around. If you're strapped for time, the bullets below will give you the broad strokes.
- Longer Prompts Are Better Prompts: Early prompt engineers discovered that longer prompts work better, thanks to their additional details, examples, and context.
- Prompting Models to Reason: "Chain of thought" prompting techniques encouraged models to provide their own context, by asking them to think step-by-step.
- Training Models to Reason: We taught models to reason during training by curating and creating examples of reasoning data and scoring their reasoning processes during fine-tuning.
- The Arrival of OpenAI's o1: o1 proved training models to reason delivered a step-change in performance, and demonstrated this improved if we simply let models think longer.
- DeepSeek's Splash: DeepSeek's R1 made reasoning a household name thanks to a free chatbot and visible reasoning. But the team's research underlined the limitations of reasoning models.
- The Strengths & Limits of Reasoning Models: Reasoning models deliver outsized performance in quantitative fields, like math and coding, but only slightly move the needle in qualitative domains.
- The Impact of Reasoning Models: The rise of reasoning models shifts the share of compute towards inference and will create an AI perception gap among users.
Longer Prompts Are Better Prompts
Following the arrival of ChatGPT, many began experimenting with best practices for prompting. Often these were little hacks that resulted in better responses. A few were somewhat absurd, like promising to tip the LLM or not punish it if it produces a good answer (I’m not joking).
One of the most important discoveries was that short prompts are bad prompts. When we provide LLMs with plenty of details, context, and examples, we get better answers. There are a few ways to do this:
- Provide more detailed instructions: Be explicit, detailed, and exhaustive about the task at hand. State the core task at the beginning of the prompt and reiterate it at the end.
- Provide examples of ideal interactions: Give examples of ideal output given an input. Provide one or several examples, each illustrating the desired outcome in different ways. You may have heard the term “zero-shot”, “one-shot”, or “few-shot.” This is what they’re referring to; replace “shot” with “examples” and you’ve got it.
- Provide additional context: Append documents, definitions, documentation, and other references to draw upon. You may have heard the term “RAG”, or “Retrieval-Augmented Generation” – this is that. LLM prompts are augmented with relevant information retrieved from a dataset.
All of tactics make prompts longer and give LLMs more explicit instructions, references, and examples to complete the task at hand, yielding better results.
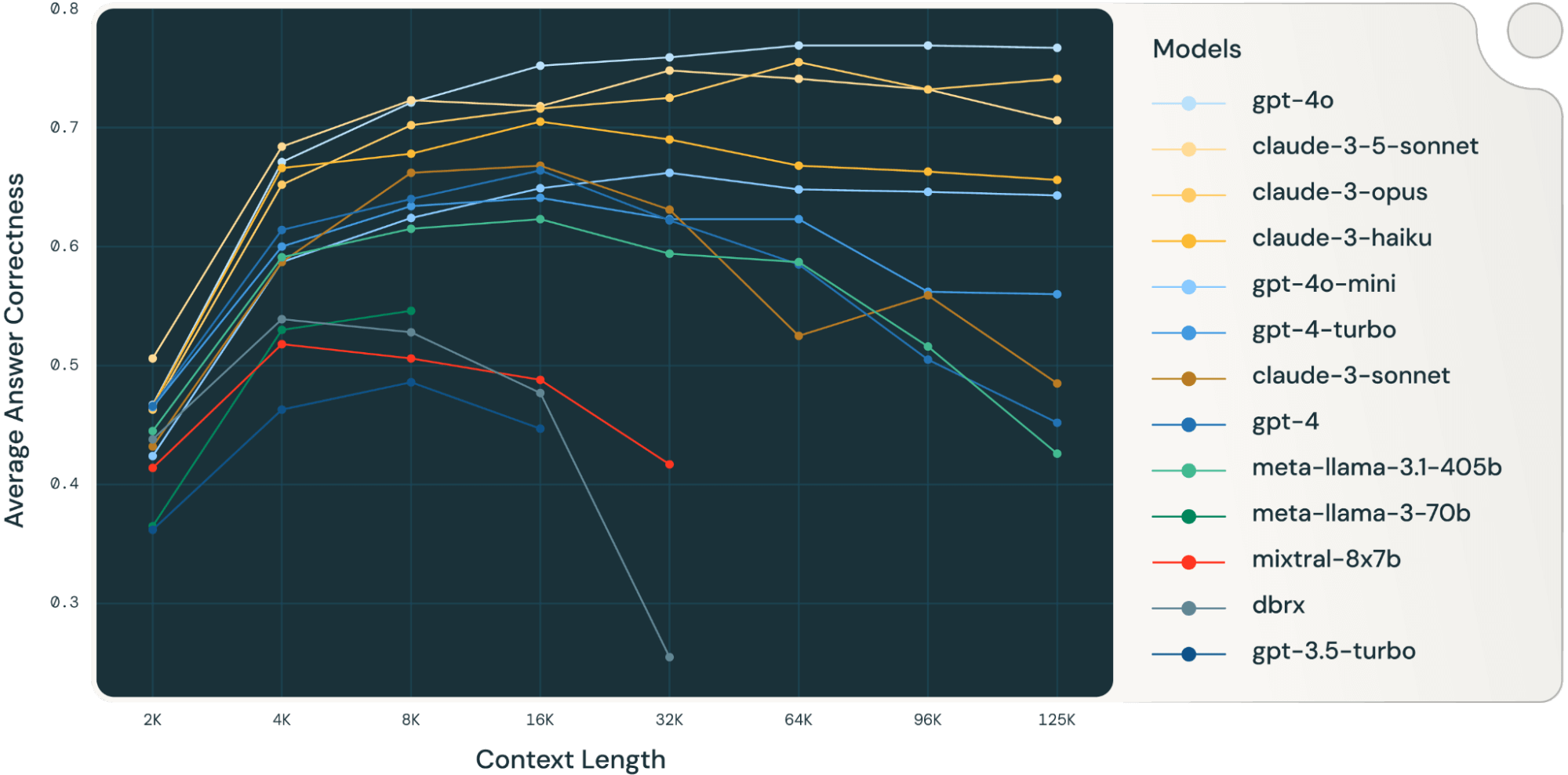
Across a range of benchmarks, longer prompts perform better. There is some diminishing performance, but the optimal range for the models analyzed above is 16k to 64k tokens, which equates to 12,000 to 48,000 words (or 24 to 96 pages of single-spaced text) – dramatically longer than most casual prompts.
Why does this work? At their core, LLMs are next-token prediction machines, constantly forecasting the most likely word to come next. Crucially, they consider ALL preceding tokens in a prompt when making these predictions, not just the most recent ones. Each additional token we provide effectively reduces the “surface area” of possible interpretations, narrowing the model’s prediction space and minimizing ambiguity about the task.
It’s similar to playing 20 Questions — it’s much easier to guess the answer after 19 questions versus just one. By providing extensive context, examples, and specific instructions, we’re essentially giving the model more “questions answered” before it needs to respond, allowing it to focus its capabilities on a much more precise understanding of our intended task rather than having to make broad assumptions about what we want.
Prompting Models to Reason
When there are more tokens to work with, LLMs perform better. This doesn’t just apply to input tokens. Generated output tokens – the ones models produce as they respond to your prompts – are taken into account when determining the next token.
In fact: output tokens are treated the same as input tokens. Therefore, if a model spends more time answering it’s effectively making your prompt longer.
So if we can convince the model to expound a bit before directly answering your input we stand to get better answers.
During those aforementioned early days of prompt engineering, people discovered that asking a model to “think out loud” or “show their work” before they issue a final answer often yielded better results. You can still do this today, with non-reasoning models. Just append the magic words – “Think step by step!” – to the end of your prompt.
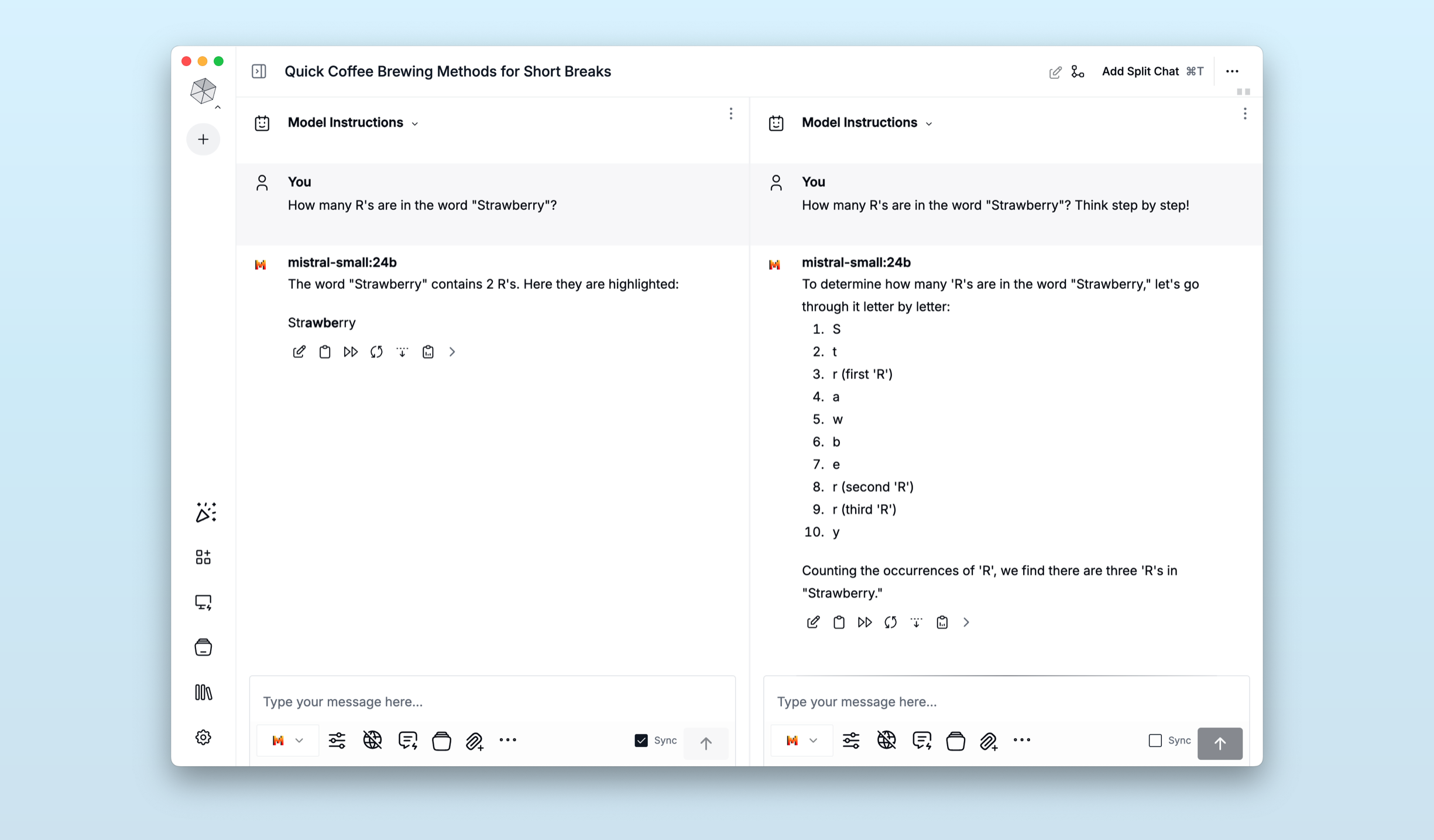
Mistral Small 3.1 isn’t a reasoning model, but by simply appending, “Think step by step!” to the end of our request we can get it to act – and perform – like one.
This prompting technique is called, “Chain-of-Thought Prompting” or “CoT.” It’s deployed quite often, still, in many LLM-powered pipelines. In our recent post on the importance of building your own evaluations, using chain-of-thought strategies increased Llama 3.2’s performance on our Jeopardy questions benchmark by 14%.
CoT’s ability to improve LLM performance surprised researchers. Models hadn’t been explicitly trained to think step-by-step. Yet here they were, able to string together reasoning steps and hone in on better answers.
But what if we purposely trained models to reason? Would we see similar gains?
Training Models to Reason
To understand how we might train models to reason, let’s back up and review the training stages used for most LLMs. Roughly, the process goes like this:
- Pretraining establishes the foundation. Massive amounts of textual data are fed into the model to provide it with diverse knowledge and general language abilities. Models at this stage are great at predicting the next token, but if you ask it a question it won’t directly answer it; it’ll just guess the next token as if it were continuing your thought.
- Fine-tuning teaches the model to converse. With the base established, we enter what is often called the “instruction tuning stage,” a fancy way to say, “let’s be sure the model replies in a way our users expect it to.” Here the model learns how to converse and interact with users. Initially, this work was done entirely by humans, but now we have large datasets that serve as examples for fine-tuning.
- Alignment makes the model helpful. Our knowledgable, conversant model isn’t quite ready for the real world. The final stage, alignment, can be thought of as a finishing school for bots: training focused on making the model helpful, honest, and harmless.
During the first two stages, we can coax models to reason.
Teaching Reasoning During Pretraining
If we have a sufficient amount of reasoning examples, we can use them during pretraining. However, most content used to train LLMs doesn’t come in this format and hiring humans to create reasoning content is prohibitively slow and expensive.
Meta’s Llama and Microsoft’s Phi teams eschewed humans altogether and used LLMs to rephrase high-quality data into step-by-step reasoning formats. As we previously wrote, in our synthetic data explainer:
[The Phi-4 team] created question datasets from sources like Quora, AMAs on Reddit, or the questions LinkedIn prompts you to answer. High-quality content demonstrating, “complexity, reasoning depth, and education value,” was selected from web pages, books, scientific papers, and code. Much of Microsoft’s previous Phi work dealt with this filtering methodology. In some cases, these high-quality selections were rephrased into Q&A content, similar to the previous example. All of this went into their seed pile.
Using GPT-4o as a teacher, the team transformed the seeds into synthetic data, “through multi-step prompting workflows..rewriting most of the useful content in given passages into exercises, discussions, or structured reasoning tasks.” This synthetic dataset made up 40% of Phi-4’s training data.
Rephrasing much of their pretraining corpus to teach Phi-4 reasoning from the start paid off: with just 14 billion parameters, Phi-4 outperforms GPT-4o (which likely has hundreds of billions of parameters) on graduate-level STEM and math evaluations.
Teaching Reasoning During Fine-Tuning
During the fine-tuning phase, a technique called “Reinforcement Learning” is usually deployed. Reinforcement Learning, or RL, is a process where a model’s output is scored, and this score is used to update the model’s weights. This score can be assigned by a human reviewer (otherwise known as “Reinforcement Learning from Human Feedback”), a computer program, or another LLM.
RL was a game-changing development in the LLM space – ChatGPT’s success can directly be tied to OpenAI’s use of human reviewers to teach GPT-3 how to converse effectively. Further, as models grew in size, RL was a crucial technique for improving the performance of smaller models. Small models could effectively go to school using RL, using large models as teachers scoring their work, with dramatic results.
To adapt RL for reasoning models, researchers began scoring each step taken by a model not just the final result. Referred to as “Process Reward Model” or PRM, this tactic unlocked the reasoning models we know today.
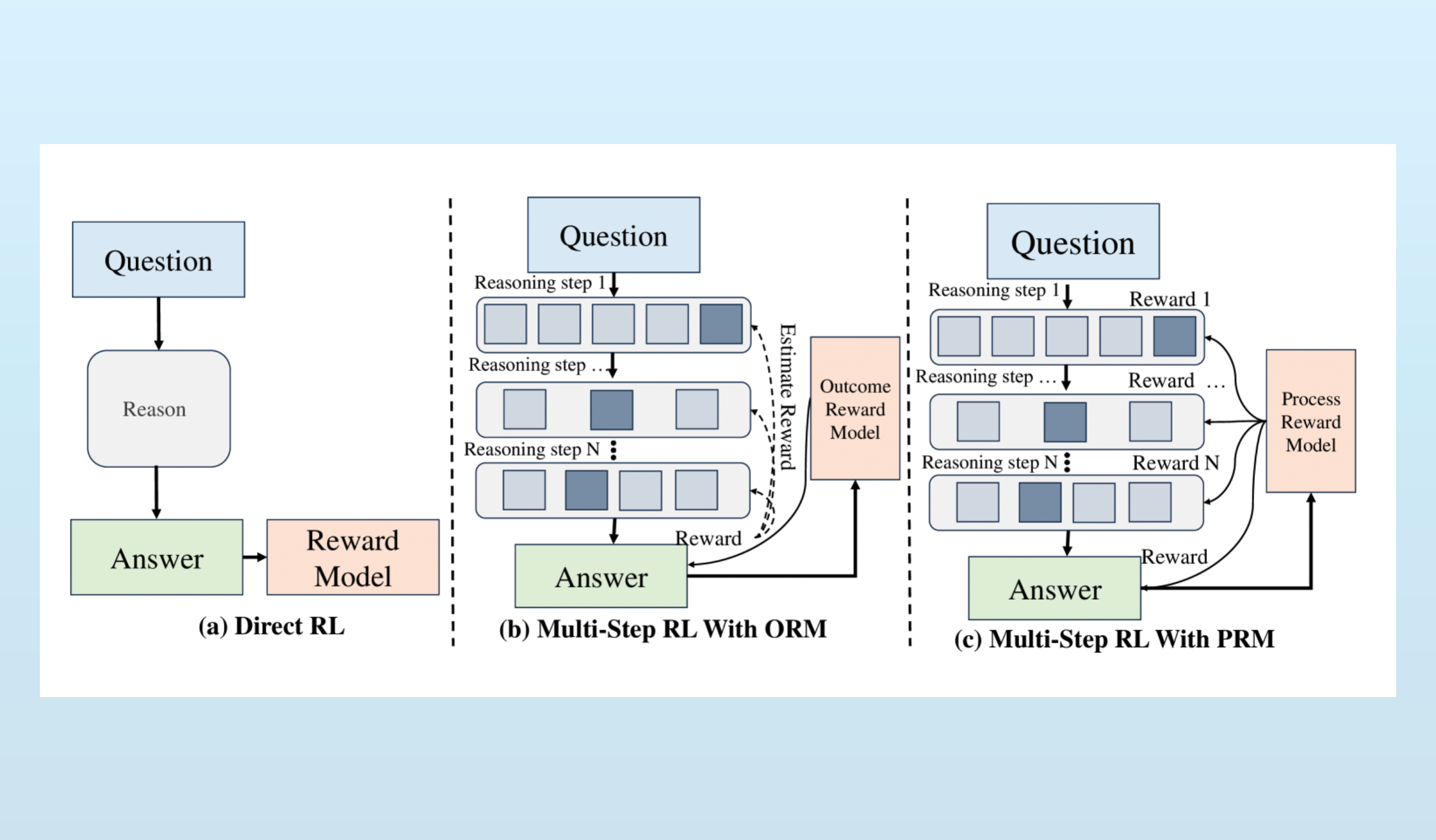
Before PRM, reinforcement learning only scored a model’s output after it was done generating it. However with PRM, individual reasoning steps were scored as the model was working. This in-process feedback encouraged models to iterate on ideas and backtrack several steps if they arrived at a dead end. The reasoning produced when using PRMs wasn’t linear, but complex.
Three reasoning techniques emerged through reinforcement learning using process reward models:
- Searching: Models learned to explore multiple, candidate solution paths to solve a single problem.
- Reflection: Models learned to identify unpromising intermediate results and course correct.
- Factoring: Models learned to break complex problems into simpler components.
These techniques enable models to essentially reason nearly forever, fracturing problems into subproblems, evaluating multiple approaches for each, breaking those approaches into subproblems… Etc. How long we let models think is up to the user, their budget, schedule, and the task at hand.
The Arrival of o1
The first major reasoning model trained with PRM, OpenAI’s o1, dramatically proved the efficacy of the technique. o1’s performance on math and coding benchmarks was a step change beyond previous scores:
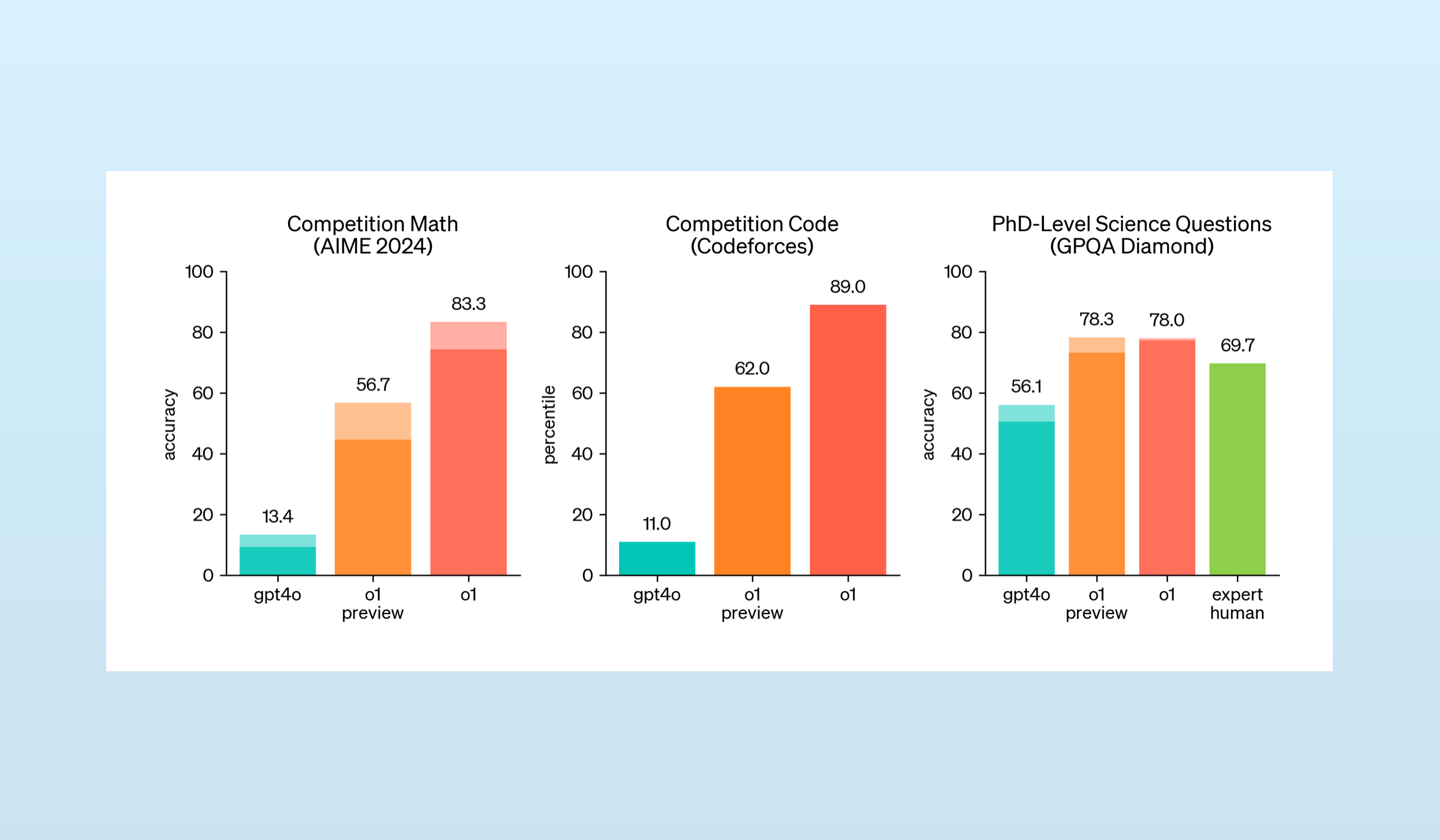
Critically, OpenAI noted that o1’s performance improves not just through additional training but also when given more time to “think” through problems.
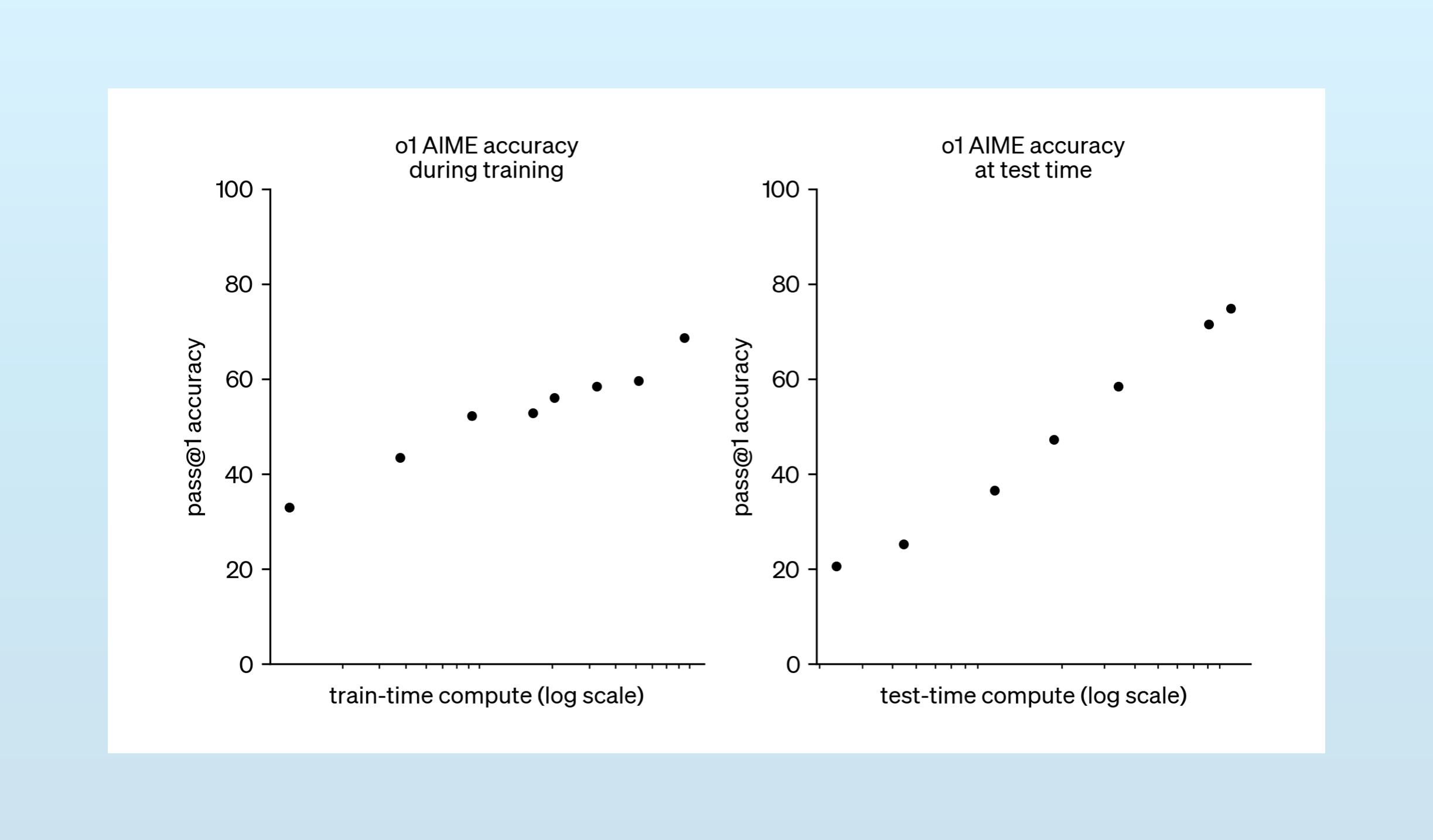
The chart above introduced a new concept, “test-time compute,” which has remained the focus of frontier model builders ever since.
“Test-time compute,” is a fancy way of saying, “how much time a model spends responding to a prompt.” The reasoning tactics models developed with PRMs – searching, refactoring, and factoring – enable them to think for as long as we wish. And this, OpenAI established, is just as valuable a lever for increasing model performance as pretraining.
Since o1, increasing test-time compute is the chief way AI labs have been increasing the ceiling of LLM performance.
Last December, OpenAI released their o3 model, which delivered a step-change result compared to o1 on ARC-AGI, a notoriously hard AI reasoning benchmark:
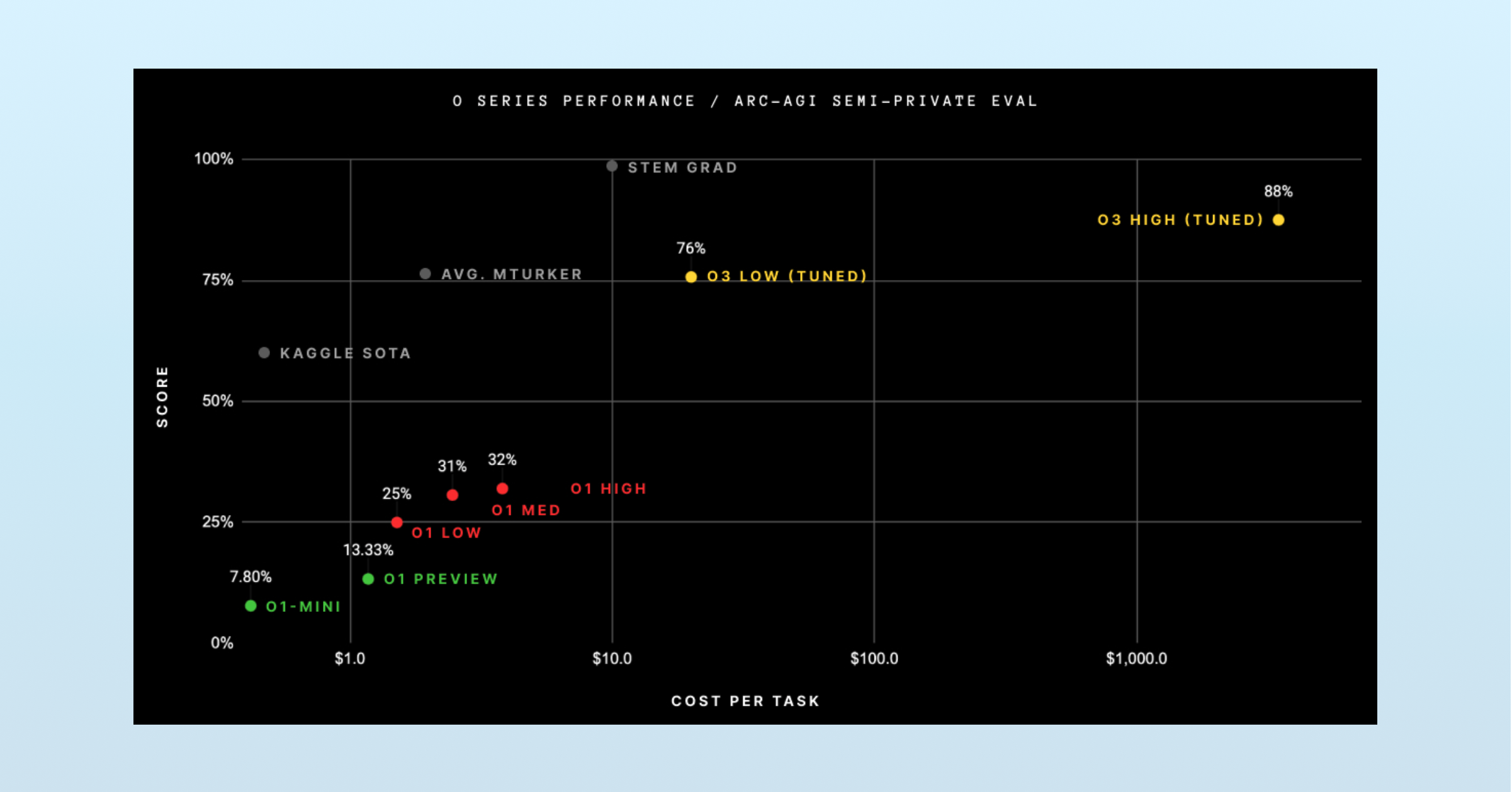
o3 was a step up, but the key to victory here was simply letting these models run for incredible durations. The yellow “o3 Low” dot on the chart above cost $6,677 to run. OpenAI didn’t share the costs for the “High” dot, but an ARC-AGI blog post says it used 172x more compute than the “Low” dot (implying a cost of more than $1 million).
DeepSeek’s Splash
If o1 proved to the LLM ecosystem that reasoning was worth pursuing, DeekSeek sold the idea to the masses. Partially this was due to the accessability of the model; trying it out was free and easy. Partially this was due to the UI for DeepSeek’s chatbot; the reasoning tokens were visible and streamed out as they were generated, allowing users to watch the model work its way through a problem. o1, on the other hand, remained behind a paywall and hid its reasoning from users.
How DeepSeek delivered an incredible model so cheaply1 is beyond the scope of this article, but DeepSeek’s reasoning model is worth reviewing because the team published their training methodology, which revealed some novel tactics and insights into how reasoning models are constructed.
Unlike OpenAI, the DeepSeek team did not use process reward models (PRMs) during reinforcement learning. Instead, to build their R1-Zero model they relied solely on reinforcement learning that judged the final output of the model. Left to its own devices, the R1-Zero model learned that longer answers were more likely to result in correct answers. As training progressed, the model increased the time it spent on each problem:
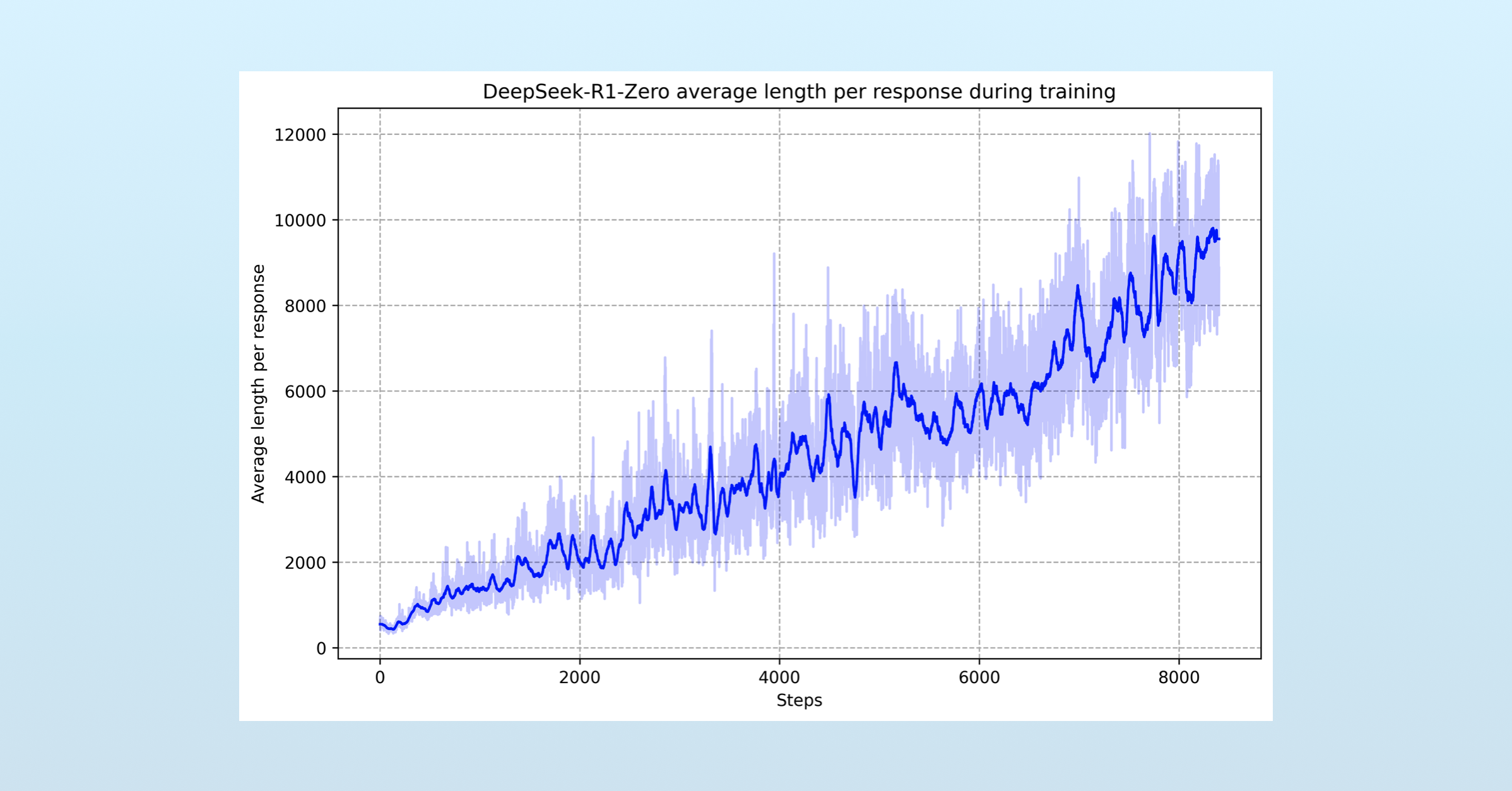
In the above image, we can see the average length of the model’s responses continually increased as it went through additional training. Rather than fine-tuning their base model with examples of reasoning data, the DeepSeek team just used RL and the model brute-forced it.
So why didn’t DeepSeek use PRMs? The team listed a few reasons, but primarily it was because they didn’t use other LLMs to judge the correctness of results because they found it would lead to “reward hacking.”
A Reward Hacking Digression
“Reward hacking” is worth spending some time on. During reinforcement learning, the model being trained often finds unexpected ways to maximize its score without achieving the intended goal. This is “reward hacking,” and it’s the bane of RL engineers. Here’s a few examples of reward hacking during RL, compiled by Lilian Wang:
- “A robot hand trained to grab an object can learn to trick people by placing the hand between the object and the camera.”
- “An agent trained to maximize jumping height may exploit a bug in the physics simulator to achieve an unrealistically height.”
- “An agent is trained to ride a bicycle to a goal and wins reward whenever it is getting closer to the goal. Then the agent may learn to ride in tiny circles around the goal because there is no penalty when the agent gets away from the goal..”
Reward hacking: the monkey’s paw of machine learning.
As we covered earlier, initial reinforcement learning efforts involved humans. Workers, usually contractors, would provide feedback to models to teach them how to converse and be honest, helpful, and harmless.
As labs used RL more and more, the cost and speed of human workers became a bottleneck. To address this, teams started using LLMs to provide feedback. A larger model serves as a “teacher”, training a smaller and/or new “student” model. This teacher model will evaluate the student model’s results, providing feedback which is then used to further train the student model.
This “teacher model” pattern scales up much better than humans, keeping costs low and training times short (at least compared to RL from human feedback). However, the imperfect nature of LLMs makes this pattern especially susceptible to reward hacking. So much so, that the DeepSeek team eschewed the pattern entirely.
So if they didn’t use models to evaluate model output, what determined correctness during RL?
In their paper, the DeepSeek team provides two examples of how they evaluated responses. For math problems, they simply compared the provided result with the known result. For coding problems, they used a compiler to ensure the code response could in fact run and compared the compiler output to predefined test cases. No other examples were provided.
Immediately we see an issue: these RL tactics only work for problems that can be quantifiably validated. Sure, DeepSeek showed that models can learn to reason with only reinforcement learning. But this skill can only be elicited in fields with objectively testable results.
The Strengths & Limits of Reasoning Models
Reasoning models deliver outsized performance in quantitative fields, like math and coding, but only slightly move the needle in qualitative domains.
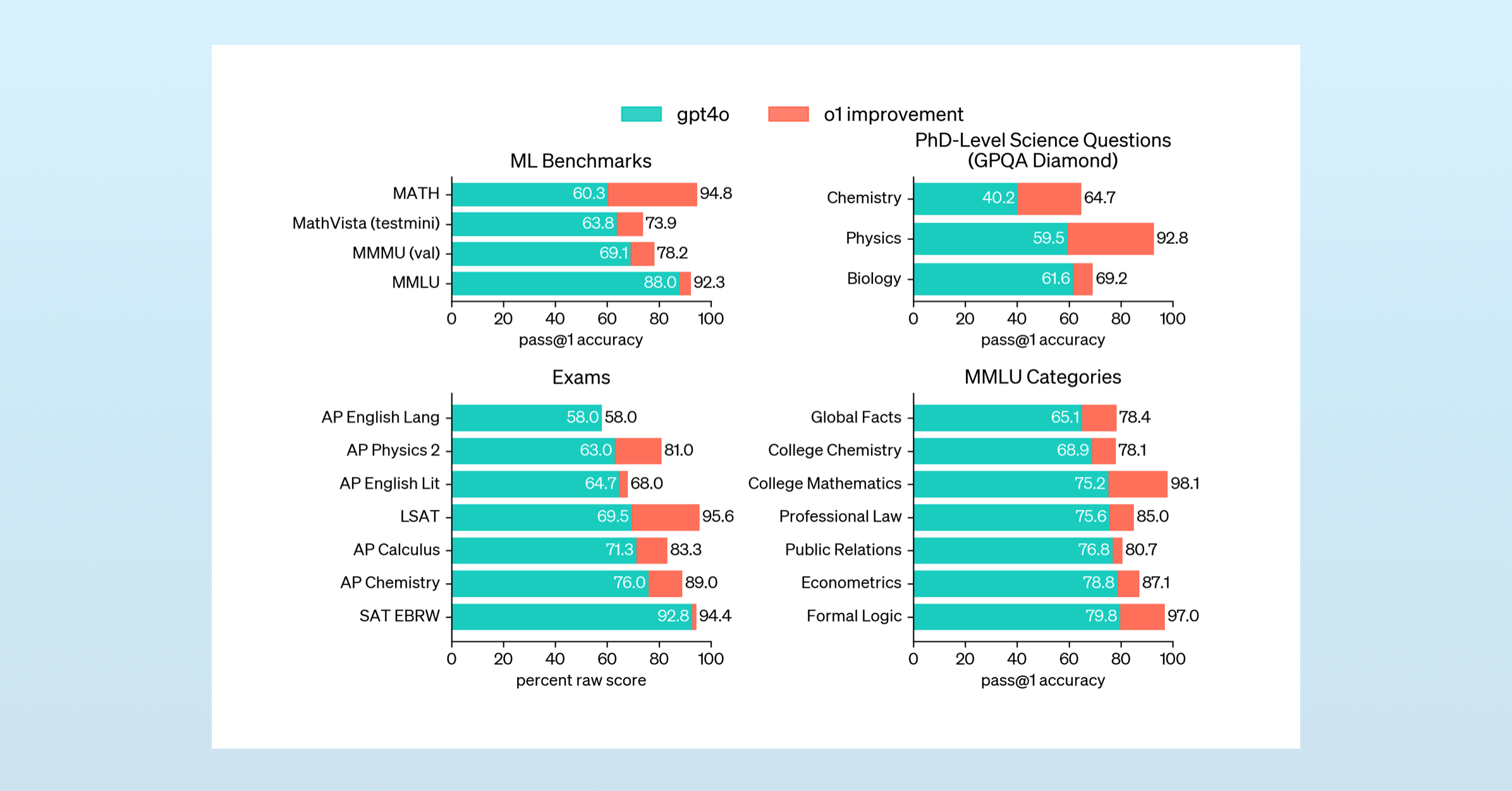
This limitation was immediately apparent with o1, whose English Literature and English Language scores closely matched non-reasoning models. DeepSeek’s R1 paper explained why the limitation existed. Reinforcement learning is necessary to teach models to reason, but only when performed on a scale where the cost and speed of human reviewers is prohibitive. To train a model to reason, you can either use a teacher model and risk reward hacking or you can limit yourself to validatable problems.
Beyond the fields of coding and math, reasoning models can help with casual queries. Their ‘thinking’ functionally extends simple prompts, providing further context that allows LLMs to hone in on better answers. But this doesn’t outperform good prompts; the ceiling of total performance remains stubbornly similar to non-reasoning models.
And reasoning comes at a cost. More output costs more and takes more time, usually several multiples higher. They should be used strategically: when you want to explore the many facets of a question, plan an approach to a challenge, or when a non-reasoning model fails to solve a bug in your code.
But for most questions reasoning is overkill. It’s slower, more expensive, and barely better than a non-reasoning model for general use.
The Impact of Reasoning Models
How will the rise of reasoning models change the AI ecosystem?
- The best models think longer: “Test-time compute” (aka, spending more time printing tokens to reason about a problem) is now fully established as a new scaling law.
- Compute needs are shifting to inference: To support longer thinking, we need to run models longer. As scaling pretraining delivers diminishing returns (see GPT-4.5’s and Llama 4’s lackluster reception), a greater share of AI compute will be used for inference.
- Models will keep getting better at testable skills: Quantitive domains – like programming and math – will continue to improve because we can use unit tests and other validation methods to create more synthetic data and perform more reinforcement learning. Qualitative chops and knowledge bank capabilities will be more difficult to address with synthetic data techniques and will suffer from a lack of new organic data.
- An AI perception gap will emerge: Those who use AIs for programming will have a remarkably different view of AI than those who do not. The more your domain overlaps with testable synthetic data and RL, the more you will find AIs useful as an intern. This perception gap will cloud our discussions. (I have only seen Scott Rosenberg at Axios (of all places!) touch on this growing divide).
- Usage data becomes more valuable: At the scale needed for reasoning training, human-powered RL is prohibitively expensive and slow. However: your ChatGPT usage today is slowly chipping away at that requirement. Companies successful at capturing user share – OpenAI, Anthropic, Google, and Meta – will have a hard-to-beat advantage when it comes to porting reasoning to qualitative problems.
If you want to dive deeper into these topics, I’ve written a few pieces worth your time:
- Why LLM Advancements Have Slowed: The Low-Hanging Fruit Has Been Eaten
- On Test-Time Compute: The New Game in Town
- On Synthetic Data: How It’s Improving & Shaping LLMs
-
DeepSeek’s R1 reasoning model attained math and coding performance nearly identical to o1. On the ARC-AGI benchmark, R1 scored 15% compared to o1’s 20%… But R1 did it while being 7 times cheaper. ↩